The SZZ Algorithm
Jacek Śliwerski, Thomas Zimmermann, and Andreas Zeller. 2005. When do changes induce fixes? In Proceedings of the 2005 international workshop on Mining software repositories (MSR ‘05). Association for Computing Machinery, New York, NY, USA, 1–5. DOI:https://doi.org/10.1145/1083142.1083147
What your tech lead says not to commit on a Friday, he is backed by research and not just lazy to review your code.
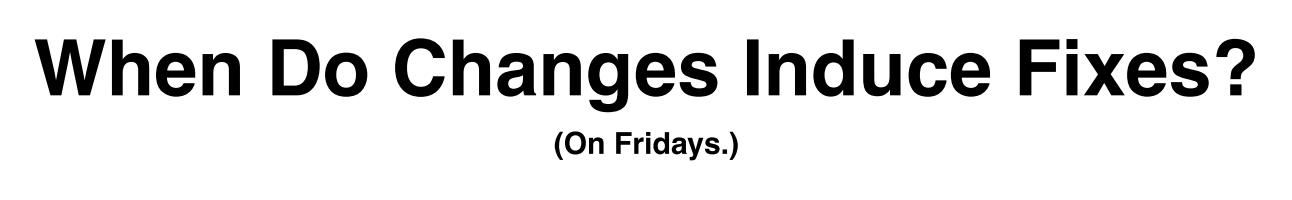
Abstract
Sometimes the code changes that developers make further induce bugs which need fixes. This paper provides a mechanism to locate such code changes and further inspects the patterns between such fix-inducing changes and the size of the commit and the day when the commit was made.
Introduction
Software development never really goes in a straight line. There is always a possibility that a commit leads to a bug. SZZ is one such algorithm that tries to detect those changes that caused a bug. The algorithm can be intuitively described as follows.
- Start with the bug report, that indicates a fixed problem.
- Get the exact code lines were changed in that particular commit, which were used to fix a problem.
- Next we can find the earlier changes that were made, in a previous commit at that location. This earlier change is denoted as a fix-inducing change.
This is definitely of interest, because one does not really want to induce a bug in the code. If it is possible to identify a commit that can potentially cause a problem, well I’d take it any day. Authors have also outlined few other reasons why identifying such a commit is desirable.
- To identify which properties of a commit can cause a problem. There can be other correlations like the day or time a commit was made, changes made by a certain developer or a group of developers, the possibilities are endless. This is pretty interesting, giving rise to avenues of mining developer behavior.
- To identify the possibility of errors in a code base. We can identify on an average how likely a change is fix-inducing.
- To filter out problematic changes. Any future analysis, need not take the fix-inducing change into account.
- To improve guidance along related changes. Usually, the fix-inducing commit is a part of set of commits that are a part of a feature. While describing the feature, the fix-inducing commits need not be included.
Data Collection
The data required to analyse the commits comes from the version control systems like CVS and bug tracking systems like Bugzilla.
A code change \(\delta\) transforms a revision \(r_{1}\) to a revision \(r_{2}\) by inserting, deleting or changing lines. A group of such changes form a transaction \(t\) as long as they are for the same purpose. Since CVS records file level changes, a sliding time window approach 1 is used to group the transactions.
To make the transaction groups more meaningful and precise, it is further linked to a bug report at Bugzilla. A Bugzilla report contains couple of metadata regarding the bug. There is a reporter field denoting the person who raised the bug, along with a short description and summary of the bug. There are additional comments and attachments fields which contain community discussions post which bug is assigned to a developer. A bug lifecycle contains one of the following status - UNCONFIRMED, NEW, ASSIGNED, RESOLVED, or CLOSED and one of the following resolution - FIXED, DUPLICATE, or INVALID.
Usually developers associate a commit with a bug report number in the commit message when they fix a bug. Using this relation, a database of the bugs and the associated commits is created 2.
A link \((t, b)\) between a transaction \(t\) and a bug \(b\) has syntactic level property and a semantic level property.
Syntactic Analysis
Syntactic analysis uses the commit message to link the commit to the bug. A commit message is first parsed into tokens. A token can be one of the following.
- Bug Number - if it matches the regex.
bug[# \t]*[0-9]+pr[# \t]*[0-9]+show\_bug\.cgi\?id=[0-9]+\[[0-9]+\]
- Plain Number - which is a string of digits
[0-9]+ - Keyword - if it matches
fix(e[ds])?|bugs?|defects?|patch - Word - which is a string of alphanumeric characters
Syntactic confidence is a number between 0 and 2. It is initialised to 0, and incremented if the following rules are satisfied.
- The number is a bug number.
- Log message contains a keyword OR contains plain number or bug number.
For example,
Fixed bug 53784: .class file missing from jar file exportThis message contains a bug number53784and a keywordFixedwhich makes the confidence as 2.52264, 51529Confidence is 1 as they only have bug numbers.Updated copyrights to 2004Since there is no valid token, the syntactic confidence is 0.
Semantic Analysis
Semantic analysis leverages the metadata captured in the bug report. The semantic confidence is initialised to 0 and incremented when the following rules are satisfied.
- If the bug \(b\) has been resolved as FIXED atleast once.
- If the description of \(b\) is captured in commit message of transaction \(t\).
- If the person assigned to the bug \(b\) has committed the transaction \(t\).
- One or more files committed in transaction \(t\) are mentioned in bug \(b\).
For example (This is modified from the paper for better clarity),
Fixed bug 53784: .class file missing from jar file export.There exists a bug with a description “.class file missing from jar file export” and the author of the commit is assigned to this bug. The resolution status is FIXED. Therefore, the semantic confidence is 3.
Locating Fix Inducing Changes
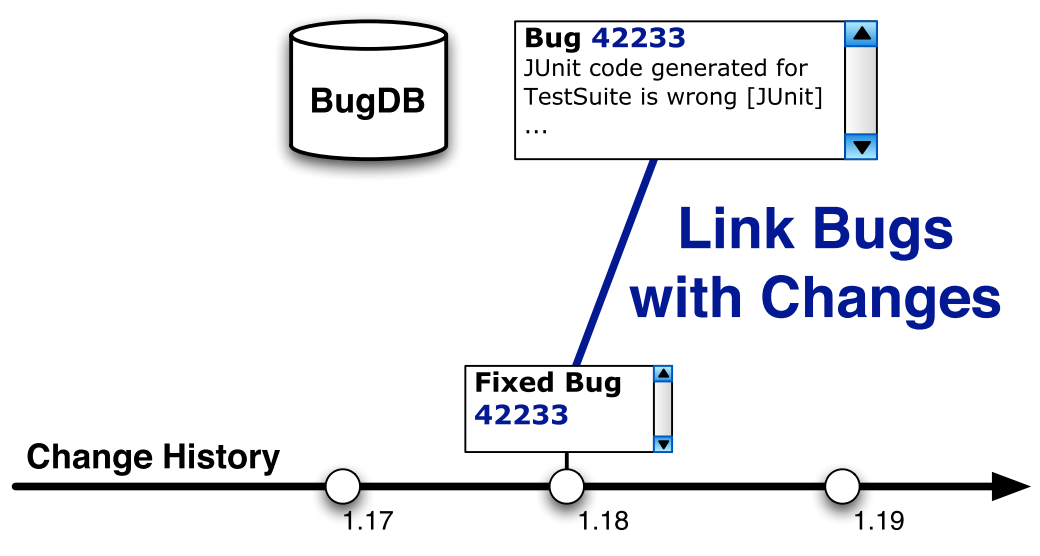
Assume code change \(\delta \in t\) transaction, which is a code fix for bug \(b\), transforms the revision \(r_{1}\) to \(r_{2}\). There can be an addition, deletion or modification of code lines \(L\), which are denoted as the the locations of the fix.

The revision \(r_{2}\) contains the correct code after the fix, while \(r_{1}\) contains the wrong code that resulted from a fix-inducing change. Therefore, to get the exact code change done, for each line \(l \in L\), the code in revision \(r_{0}\) is found. Once the candidates for the fix-inducing changes are found, they further need to be filtered out based on the date the particular commit was made.
A pair \((r_{a}, r_{b})\) is said to be a suspect for the fix-inducing change, if \(r_{a}\) was committed after the bug has been reported with \(r_{b}\). A suspect change cannot cause a fix-inducing change. Similarly,
- \((r_{a}, r_{b})\) is a partial fix, if \(r_{a}\) is a fix as it is possible that \(r_{a}\) is a part of a fix spanning multiple transactions.
- \((r_{a}, r_{b})\) is weak suspect if there exists another pair \((r_{a}, r_{c})\) in the transaction which is not a suspect, as it indicates that there is another avenue for for it to be fix-inducing.
- \((r_{a}, r_{b})\) is a hard suspect if it is neither a partial fix, nor a weak suspect. It just means that there is no evidence that this pair is fix-inducing.
Finally, a revision \(r\) is fix-inducing, only if there exists a pair \((r, r_{x}) \in S\) which is not a hard suspect.
As an extension, a transaction \(t\) is fix-inducing if it contains a fix-inducing revision.
Results
Authors experiment with the codebases of Mozilla and Eclipse, and observe similar trends on analysing both the codebases.
- Fix-inducing changes are larger, roughly three-times, compared to the non fix-inducing changes.
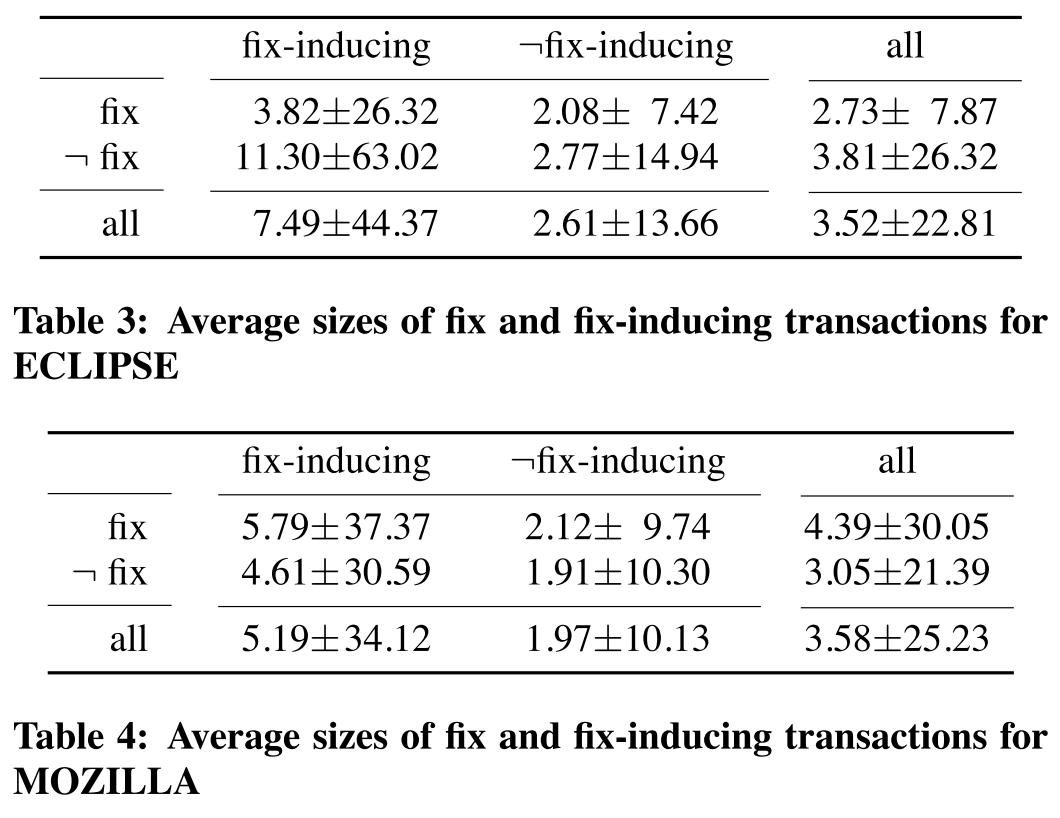 Relationship between fix-inducing transaction and its size.
Relationship between fix-inducing transaction and its size.We can infer that larger the committed code chunk, higher the possibility of it being a fix-inducing code. This can also be interpreted as since there are lot of changed code lines, there is more surface for the error to creep in, which in turn makes the code fix-inducing.
- On comparing the fix-inducing commits with respect to time, it is seen that there is a higher possibility of a code being fix-inducing if it is committed on Fridays or weekends.
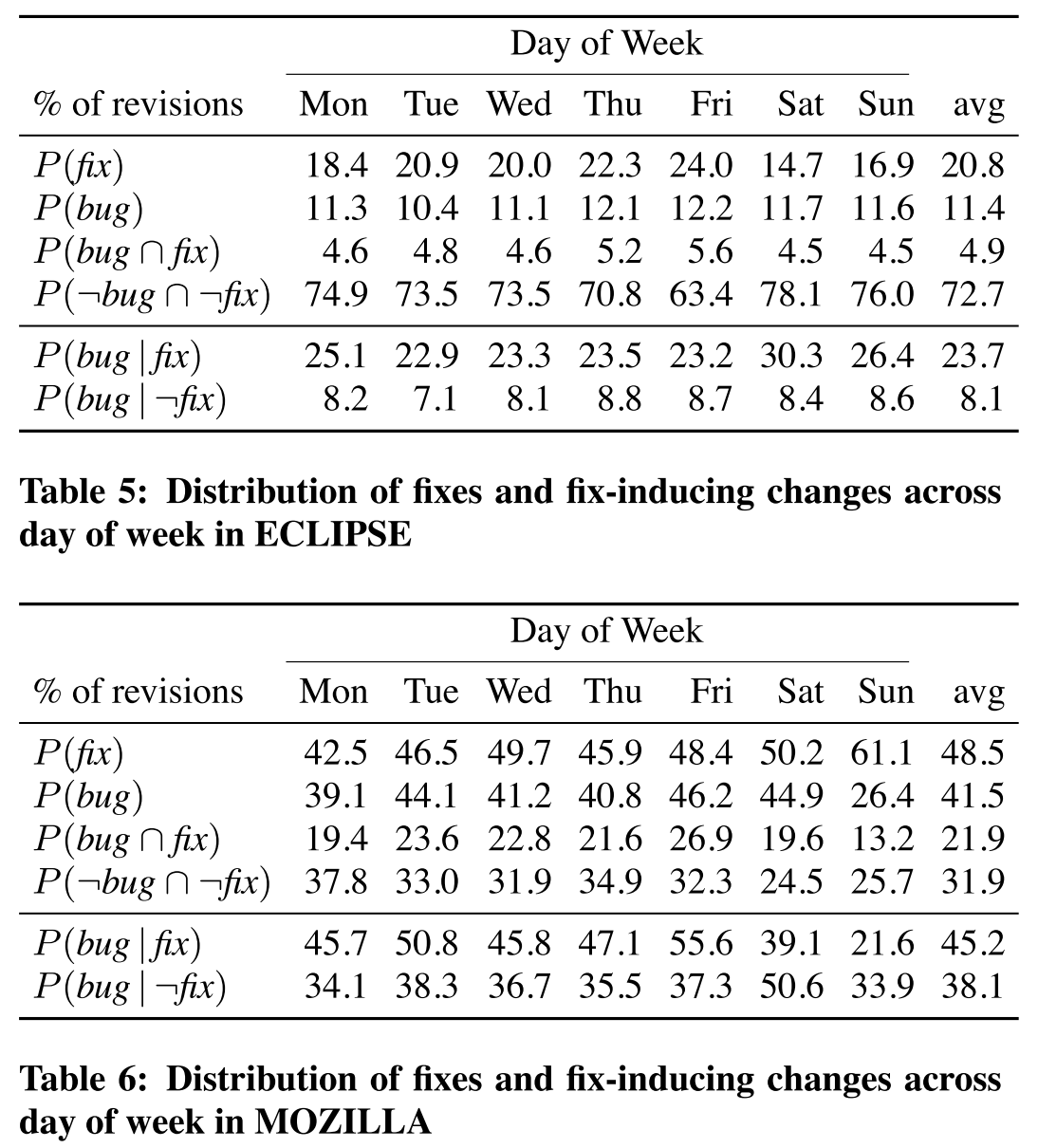 Relationship between fix-inducing transaction and commited day.
Relationship between fix-inducing transaction and commited day.
This can also be due to the fact that most developers try to commit their work before the weekend, and resume it from the following week.
Conclusion
The paper proves that the relationship between the bug archive and code repository can lead to interesting results, and every project can be independently diagnosed with any such relationship and administered better. The two results that are described in the paper are only a subset of several insights that can be hypothesised from data gathered from the algorithm. Authors also mention that such relationships can be extracted between the code modules and the developer group which can further aid the project manager or the tech lead to devise a better strategy towards commits and code reviews.
Definitely, visualizations on these results will help non technical people understand their team better.
Primary topic interest in the paper is the SZZ algorithm which is relevant even after 15 years. The advent of hash based version control system like Git can probably make the grouping of the commits into a transaction easier to model while compared to CVS.