Can you repair compilation errors with Deep Learning?
Mesbah, Ali, Andrew Rice, Emily Johnston, Nick Glorioso, and Edward Aftandilian. 2019. “DeepDelta: Learning to Repair Compilation Errors.” In ESEC/FSE 2019 - Proceedings of the 2019 27th ACM Joint Meeting European Software Engineering Conference and Symposium on the Foundations of Software Engineering, 925–36. Association for Computing Machinery, Inc. doi:10.1145/3338906.3340455.
As developers, we all spend hours in debugging the code, so that it compiles fine. While the days of breaking our heads to find the bugs are far from over, the DeepDelta framework offers insight into an innovative approach to generate code repair changes automatically.
Abstract
While writing code is a highly logical activity, much of the process is iterative in itself. So it makes sense that any sort of error that creeps in while compilation can be fixed with following some pattern in code. DeepDelta exploits this attibute of software development, and leverage deep neural networks to predict program repairs. While compiling a program, the compiler usually spits out a diagnostic information. The error diagnostic becomes the \(x\) or source.
There is a change delta, which is nothing but the code change (or diff, when you speak in terms of Git) done to successfully compile the code. An Abstract Syntax Tree representation of this diff forms the target or \(y\). The researchers run this input data through a NMT network and train a model that gives out a success rate of 50%. There are multiple ways to fix the code too. Out of the 50% success scenarios, the predicted changes are about 86% of the time in the top three ways to fix the code, indicating the relevancy of the model output.
Introduction and Background
Usually developers fix their compilation issues manually with debuggers or traversing through code flows. Once an engineer identifies and writes what could possibly be a fix for the compile issue, he goes ahead and compiles a code again. This can be called as a edit-compile cycle. It is a highly iterative process; there could be multiple locations where the code is broken, a change for a error could result in code breaking at another location. This makes the edit-compile cycle a time consuming process.
There is a pattern in which developers change the code, in response to the errors. Obviously there is a code change done to fix the issue. These code features can be succintly represented by an Abstract Syntax Trees.
Neural Machine Translation 1 is the algorithm of choice, as it accurately captures the mapping between compilation log and AST of the delta.
Data Collection and Insights
Compilation Error Logs (or Source set)
A typical engineer at Google builds his code about 7-8 times a day. Every build initiated is automatically logged. This log contains detailed information about the build, error messages if any and a snapshot of the image that was built. This paper mainly refers to the Java errors.
Java compiler has a Diagnostic class that reports a problem at a specific position in the source file. There is a Diagnostic.Kind enum that is implemented, that captures the way it is presented to the user. There are preset templates into which concrete names are interpolated. Researchers built a parser to map the error messages to the message templates that produced them.
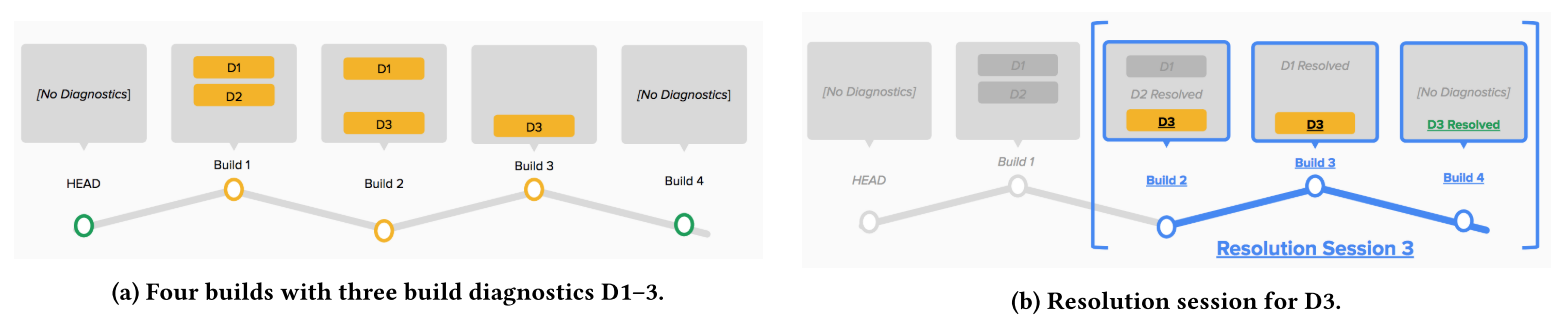
It is possible that fix for a error can lead to another error. This could mean that the fix that was done was not right, and some other fix might be necessary. Also, if there are multiple errors reported in one build, then individual fixes will have to be done for the errors. To map a fix to an error correctly, the researchers identified sequences of builds into something called Resolution Sessions.
A resolution session (RS) for a build diagnostic Di is a sequence of two or more consecutive builds, B1 , B2 , …, Bk where Di is first introduced in B1 and first resolved in Bk , and the time between build Bn and Bn-1 is no more than a given time window T.
Essentially this captures the period of time a developer spends in resolving the issue. This brings to the next important concept called the Active Resolution Cost.
For a diagnostic Di , Active Resolution Cost (ARC) represents the active time the developer spends resolving Di , excluding the cost of the builds themselves, divided by the number of diagnostics present in the intermediate builds of its resolution session.
\[\sum_{i=1}^{k-1} \frac{Ts_{i+1} - Te_{i}}{|D_{i}|}\]
Together, these two aspects quantitatively describe an edit-compile cycle. The below image provides an example of a resolution session; Build 1 to Build 3 is the RS of D1, Build 1 to Build 2 is RS of D2 and Build 2 to Build 4 is RS of D3.
Coming to the data collection process, this is how the metrics look like.
- Around 20% of all builds fail. Out of 4.8 million builds in a period of 2 months, around 1 million were failures.
- From the 1 million failures, about 3.3 million diagnostics were extraced.
- The Resolution Session criteria filters out 1.5 million sessions where the changes were done with more than one hour between build attempts.
- From the 1.9 million, 110219 resolution sessions were identified, which contained only one single diagnostic session, resulting in a successful build. We can reason out that in these cases the change made by the developer resolved the error.
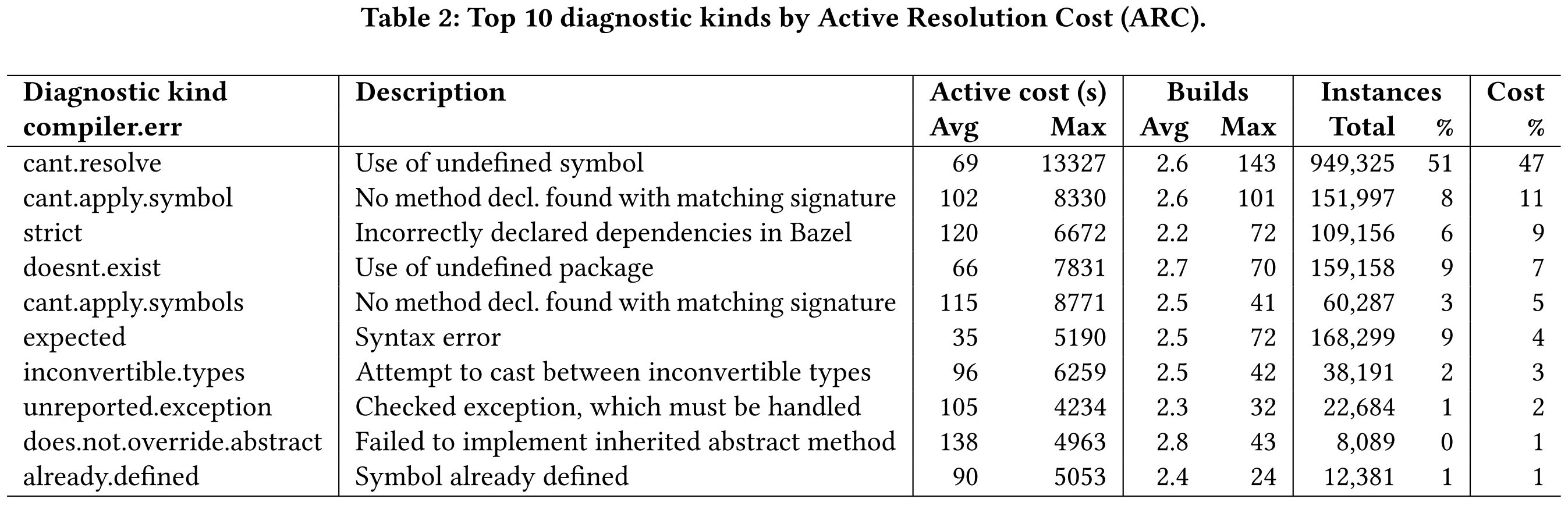
The top two build errors are cant.resolve and cant.apply.symbol diagnostic kind, which are thrown when the compiler encounters an unknown symbol and when it cannot find a method declaration with given types respectively. On calculating the ARC for the top ten errors, it amounts to 57,215,441 seconds or ~15,900 hours. The top two errors total to around 58% of the total ARC.
This means total time spent by Google engineers in resolving only two classes of errors in the span of two months comes out to around a year of developer cost!
Keep in mind, this is coming from a very small subset of about 100k resolution sessions; true numbers might really be staggering, indicating the relevancy of this research.
cant.resolve: A Running Example
Researchers have used cant.resolve diagnostic kind as a running example to explain how DeepDelta framework works. In Java, an identifier must be known to the compiler before it is used, else cant.resolve error is thrown. The developer might have not declared or mistyped an identifier, missed dependency or imports.
import java.util.List;
class Service {
List <String > names() {
return ImmutableList.of("pub", "sub");
}
}
This code throws the following error.
Service.java :4: error: cannot find symbol symbol: variable ImmutableList
This is fixed by importing the ImmutableList package.
import java.util.List;
+++ import com.google.common.collect.ImmutableList;
class Service {
List <String > names() {
return ImmutableList.of("pub", "sub");
}
}
There is a dependency that needs to be fixed as well.
java_library(
name = "Service",
srcs =[
"Service.java",
],
deps =[
--- "//java/com/google/common/base",
+++ "//java/com/google/common/collect",
],
...
)
This example shows the code diff that fixed the corresponding issue. Next step is to capture these features.
Collecting Resolution Changes (or Target set)
Two snapshots of the code, one prior to the successful build and one after, are extracted. Google stores the developer code, which makes this data easily accessible.
Next step is to automatically figure out the changes that were done between the two snapshots. This is done using a tree differencing approach 2,3. First step is generating the two ASTs.
Given two ASTs, source asts and target astt , an AST Diff is a set of vertex change actions that transforms asts into astt.
The algorithm compares the vertex labels, and detects if any vertices are unmatched. If any such vertices are found, then a short sequence of actions that transform asts to astt are computed. Since this is a NP-hard problem, certain heuristics are used to compute the transformation. The algorithm outputs a set of actions that were performed on the vertices to transform the source AST to the target.
- Moved: Existing vertex (and children) in asts is moved to another location in astt.
- Updated: Old value of a vertex asts is updated to a new value in astt.
- Deleted: A vertex (and its children) in asts is removed in astt.
- Inserted: A new vertex that was not present in asts is added in astt.
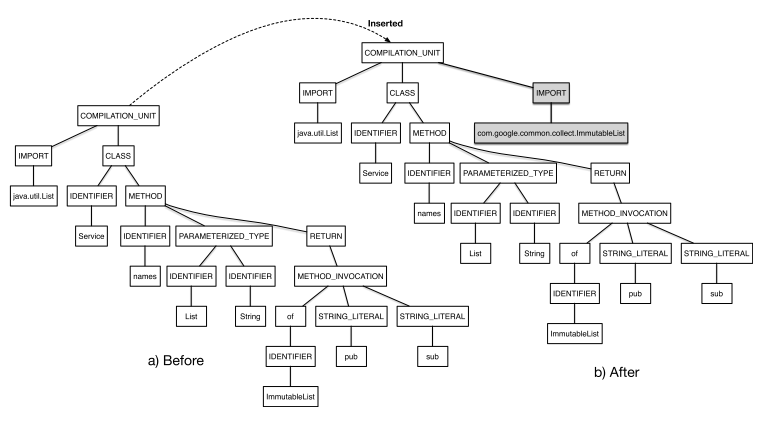
The patterns in AST Diff for a certain change can be automatically inferred and can be used for assistance for code fix.
A resolution change (RC) is an AST Diff between the broken and resolved snapshots ofthe code, in a build resolution session.
Feature Extraction and Neural Network Architecture
Building upon the concept of naturalness hypothesis 4 researchers propose that the source build diagnostic feature can be translated to target resolution change using Neural Machine Translation.
Source Features
The diagnostic specific information can be added to the source feature set. Specifically for the cant.resolve running example, the label and the location of the missing symbol can be found out from the logs, and the AST path for that symbol can be traversed.
The ASTPath AP of a missing symbol Sm is defined as the sequence of AST vertices from the root to the parent vertex of Sm on the AST of the broken snapshot.
Including the AST path as a feature provides contextual information to the neural network and can increase the accuracy between 15-20%.
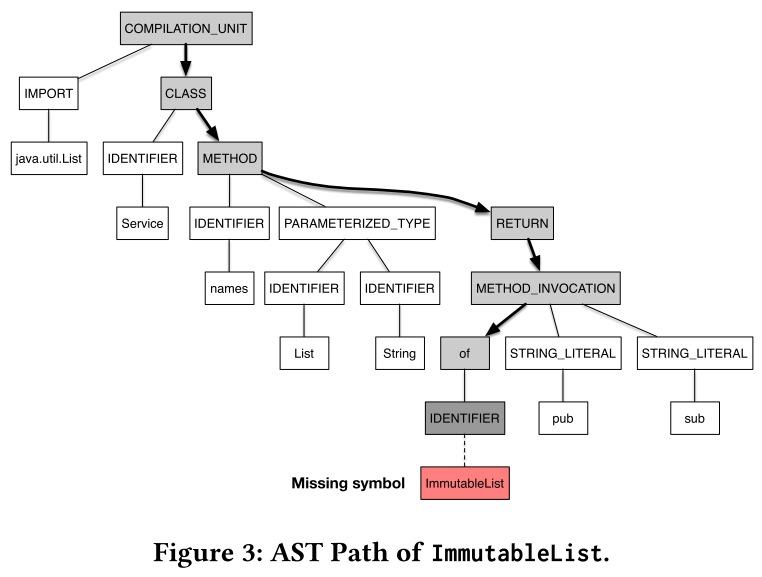
The source feature set for the cant.resolve consists of the following.
- Diagnostic Kind: compiler.err.cant.resolve
- Diagnostic Text: cannot find symbol
- AST Path: COMPILATION_UNIT CLASS METHOD RETURN METHOD_INVOCATION of
- Symbol Type: IDENTIFIER
- Symbol Label: ImmutableList
This feature set is specific to Diagnostic Kind. For cant.apply.symbol the feature gets augmented with certain other features.
Target Features
Target feature consists of the changes made to the AST. This is represented using a Domain Specific Language called Delta. The EBNF of this DSL is as follows.
Delta.grammar
resolution_change_feature
: file_type WS (change_action (WS)?)* EOF ;
change_action
:change_type WS (location WS)? single_token token_seq location WS single_token token_seq ;
file_type : 'BUILDFILE' | 'JAVAFILE' ;
change_type : 'INSERT' | 'DELETE' | 'UPDATE' | 'MOVE' ;
location : 'INTO' | 'FROM' | 'BEFORE' | 'AFTER' ;
single_token : TOKEN WS ;
token_seq : (TOKEN (WS)*)* ;
WS : (' ' | '\t') ;
TOKEN : ( COLON | QUOTE | COMMA | LOWERCASE | UPPERCASE | DIGIT | UNDERSCORE) +;
fragment UNDERSCORE : '_' ;
fragment COLON : ':'' ;
fragment QUOTE : '"' ;
fragment COMMA : ','' ;
fragment LOWERCASE : [a-z ] ;
fragment UPPERCASE : [A-Z ] ;
fragment DIGIT : [0-9] ;
There are two places where the change can be applied, JAVAFILE or BUILDFILE, indicated by the change_type field. change_type indicates the action done.
The target feature or Delta for cant.resolve Java code change is as follows.
fileType JAVAFILE
change_action
change_type INSERT
single_token IMPORT
location INTO
single_token COMPILATION_UNIT
change_action
change_type INSERT
single_token com
token_seq google common collect ImmutableList
location INTO
single_token IMPORT
Delta for the Build file code change is as follows.
fileType BUILDFILE
change_action
change_type UPDATE
location BEFORE
single_token java
token_seq com google common base
location AFTER
single_token java
token_seq com google common collect
Once the source and target feature sets are generated, they are vectorized for serving as input to the NMT.
Neural Machine Translation Architecture and Hyperparameters
The DNN used is built on top of TensorFlow, and is composed of LSTMs of 1024 units with 4 encoder and 4 decoder layers. The encoder type is the GNMT encoder, which is composed of one bi-directional and three uni-directional layers. Stochastic Gradient Descent is used as the optimizer, with 1.0 learning rate and 0.2 dropout value.
Since the code can have pretty long sequences, researchers have used the normed Bahdanau attention 5 to extend the attention span of the network.
The researchers made the model queryable by hosting it on a server. Beam Search 1 does the translation while maintaining a balance between translation time and accuracy. Input to the model is a feature \(x\) representing a failure. The inferred result is in the form of \(n\) sequences of repair suggestions, every \(\displaystyle y_{i}\) in \(\displaystyle \{y_{1}, y_{2}, ..., y_{n}\}\) is a distinct repair suggestion for \(x\) and is a series of resolution change tokens.
Evaluation and Results
The repair suggestions were evaluated with five metrics.
- Perplexity: This metric measures how well a model predicts samples. Lower the better.
BLEU score: BLEU is used in the NLP world for automatic evaluation of generated sentences. It internally uses a n-gram model to compare the human sentences and the machine generated sentences and scores the machine output with a score between 1-100 where higher the score, better the generated text. BLEU scores of 25-40 are considered good.
The model reached low perplexity values of 1.8 and 8.5 for
cant.resolveandcant.apply.symbolrespectively. BLEU scores were 42 and 43 in the same order. This indicates that the model generated is good.Syntactic Validation: A lexer and parser were generated from Delta grammer. All the inferred suggestions were passed through this, and checked if the suggestion is syntactically valid or not.
On average, 71% of the generated suggestions were valid for
cant.resolveandcant.apply.symbolhad a higher accuracy of 98%. Researchers reason out that this could be because the code changes for this error are syntactically simple.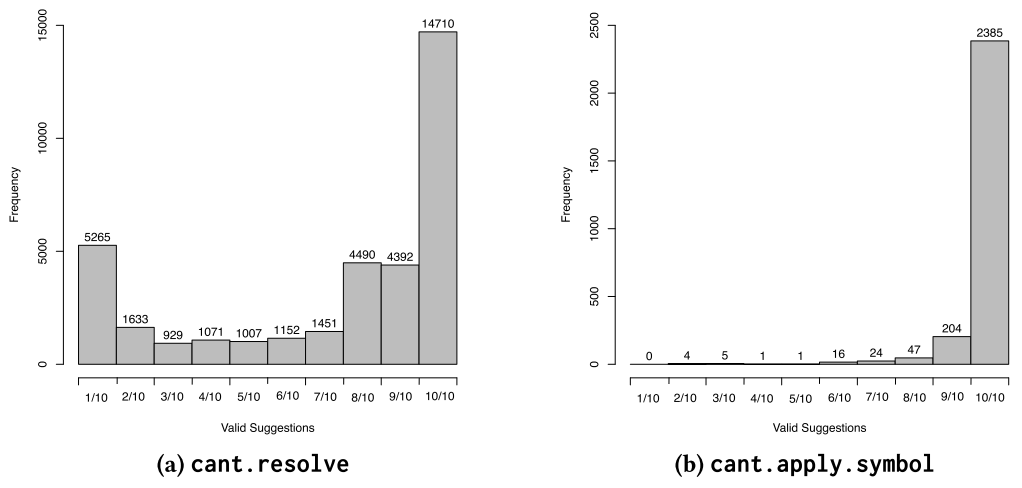 Distribution of valid suggestions over the 10 generated suggestions.
Distribution of valid suggestions over the 10 generated suggestions.Correctness of Suggestions: A suggestion is considered correct if atleast one of the 10 inferences match the fix done by developer.
This was 50% for
cant.resolveerror. Forcant.apply.symbolthe error was around 47%.Ranking of Correct Repairs: Higher the ranking of the correct suggestion in the list of 10 inferences, better the model.
For
cant.resolve85% of the correct fixes are in the top three positions, and forcant.apply.symbol87% of the correct fixes are in top three positions.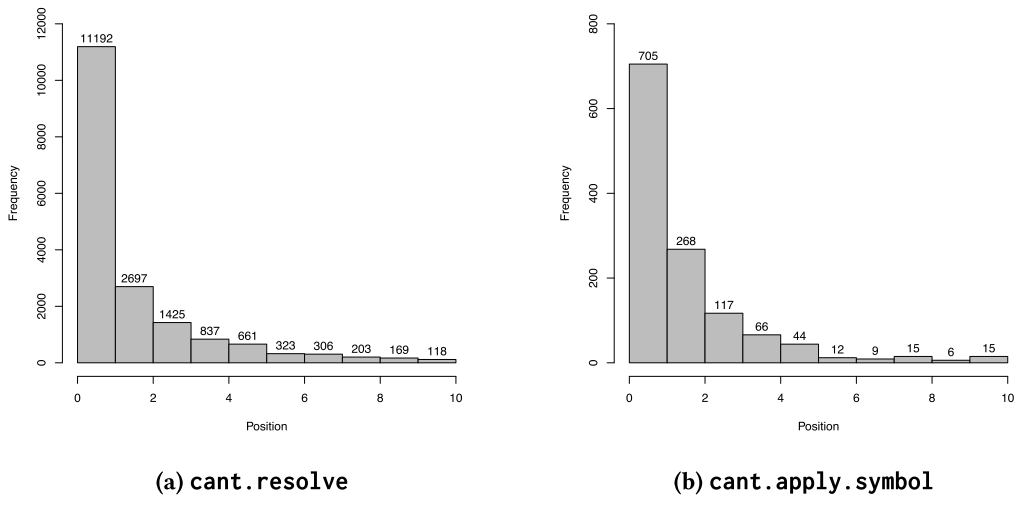 Position of correct suggestions.
Position of correct suggestions.
Discussions and Future Work
The DeepDelta approach identifies the recurrent and common patterns in how the developers resolve build errors and is able to extract it in the form of a sequence of changes that the developers can actually use to fix their compilation fixes. With 50% correctness rate, this is 23% more than the previous state of art.
There is a good possibility for the program to recommend invalid suggestions. Researchers reason out that this can be due to two factors.
One, it is possible that the vector that is predicted by the decoder might not map to a valid token in the vocabulary. This happens when the model has not learnt the change pattern.
Two, it is possible that the sequence generated does not adhere to the Delta EBNF grammer, especially for longer sequences (more than 90 tokens). There might be missing tokens at the end of the sequences.
The dataset is a industrial sized one, with more than 10000 Java projects and 300 million LOCs. It represents changes made by thousands of developers worldwide, using different IDEs. Therefore the main concept that DeepDelta leverages, which is there are patterns in how developers address a compilation issue holds good. While it sure requires work, the technique used can be scaled to other systems as well.
The most frequent repair patterns which were got from clustering the inferenced solutions are as follows.

cant.resolve ChangeAccomodating other programming languages is possible, since only the AST parsers have to be written for the particular languages. Similarly, other Java errors can be accomodated as well.
Error safe parsers harden the AST approach taken. Parsers that can recover from the syntax errors 6 need to be introduced.
Turning the Deltas to code modifications is the first of the two possible future works proposed by the authors. However, the problem statement here would be to understand where to make the suggested changes. Few examples provided by the authors for the cant.resolve example are as follows.
Add missing imports&Remove import- Location information is not required as imports are usually at the top of the file in Java programs.Change the method call&Change the missing symbol- Location of the missing symbol is known, and can be modified.Add missing build dependency&Change build dependency- Changes can be made to the dependency list.
Second possible future work is automated program repair, where the suggested fix is applied and only the fixes that compile the builds are to be presented to the users. Building an good user interface that makes the model useful to the developers is paramount.
Thoughts
The Abstract Syntax Tree approach to map the code is an innovative approach, and can be used for multiple other software engineering problems involving learning from code. It would definitely be worth trying on automated code review, or code comment generation problems.
Main problem here, as acknowledged even by the authors, would be reproducibility. There are no public datasets available on which DeepDelta can be reproduced. One possible way to address this would be to build a dataset with GitHub APIs. GitHub supports CI setups, and logs errors too, and most definitely can be used to mimic the data collection steps followed by the authors. However, this might not come close to dataset that researchers had access to in Google.
While the researchers addressed the compile-time errors in Java, there is a possible avenue into extending it to other such compiled languages like Julia or C++ even. Having such a capability in languages that are used by other disciplines (say like Statistics) can help other researchers who might not be proficient in coding. One could also think about similar patterns used by the developers in interpreted languages like Python too.
DeepDelta has good application in automated program repair. However, program builds are compute and time intensive, and applying the multiple fixes before arriving at the correct fix might not be practicle in few scenarios. One way to tackle is ofcourse by having a better ranking of the correct repairs metric. Leveraging simple classification algorithms on top of the framework might help.
Interesting References for Better Understanding
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation ↩ ↩2
Change Distilling:Tree Differencing for Fine-Grained Source Code Change Extraction ↩
Neural Machine Translation by Jointly Learning to Align and Translate ↩
A practical method for LR and LL syntactic error diagnosis and recovery ↩