Using Argumentation Models to Model Issue Threads
Wang, Wenting, Deeksha Arya, Nicole Novielli, Jinghui Cheng, and Jin L.C. Guo. 2020. “ArguLens: Anatomy of Community Opinions On Usability Issues Using Argumentation Models.” In , 1–14. Association for Computing Machinery (ACM). doi:10.1145/3313831.3376218.
How do you decide which features to implement in a software? If you are in an industry setting, then you get a list of requirements from a product owner, and is mainained by the product manager in the form of user stories. There are iteration planning meetings, and backlog grooming sessions, that allow the teams to prioritize the tasks and develop a software. There are software engineering models like Agile that logically detail out the role of every individual in a software development project.
However, this is not the case in the open source world. There is a public discussion on any forum (or GitHub) how the software has to evolve, where everyone can propose a featue and and assert its requirement.

Why does this become a problem? Because of the wild discussion that happens. Finding a relevant support or disagreement to the issue or feature gets lost in the long conversations. It is possible that some messages might be personal opinions, some may be clarifications, and some heated arguments and these might not add any value to the discussion. This makes it difficult for the developers to arrive at an decision, and do what they love the most, writing code.
Abstract
To address the problem of extracting relevant information that is available in the issue discussion threads, the reserchers have proposed and evaluated ArguLens, a model that leverages the Toulmin Model of Argument. They have analysed the long issue discussion threads and experimented with automated argument extraction. Usability testing done to understand how the feature can facilitate the understanding of opinions in issue discussions.
Introduction
The Open Source Software landscape has evolved to become a platform for developers to collaboratively advance the field. Since the tools that are developed are adopted by thousands of fellow developers, community feedback becomes important, and is done by Issue Tracking Systems or ITSs. The vast number of comments that are posted poses challenge to the contributers who are trying to understand the user needs and can affect the way a sofware is evolved.
To address this problem, there are three underlying questions that need to be answered. Paraphrasing the research paper,
How do the open source software communities argue about usability issues in issue tracking systems? This is required to understand how argumentation theory can be applied to the issue at hand.
How effective are machine learning models in extracting arguments and their structure in the issue discussions? This is required to evaluate how the issue discussion threads can be modeled and leverage the model to predict the learnings.
To what extent can argumentation enhanced representations of usability issue discussions support practitioners in understanding and consolidating community opinions and needs? This is required to address the tool’s applicability.
Background
Open Source Usability
Main challenges that developers face while tackling the usability issues in OSS are as follows
- Not understanding the specific needs of the users.
- Not having sufficient technical/functional expertise to work on an issue.
- Focus on optimising the software features which leads to complexity, rather than working to make it easy to use and maintain.
ITSs are useful to address these, by providing a common platform for the community to discuss usability issues. However, they are also subject to limitations like lacking support in classifying defects and handling discussions, not being able to accomodate different communication styles and can also lead to information overload and therefore hinder the participation and contribution.
This makes it one of the important problem to address.
Argumentation Theory and Its Application to Usability
Everyone has had an argument. A structured aregument is important in areas like knowledge representation, legal reasoning and negotiation and this led to development of an area called argumentation theory that studies the structure of the arguments. ITSs can be a good place where the argument theory can be applied to software engineering.
One of most influential argumentative model is Toulmin’s model of argumentation.
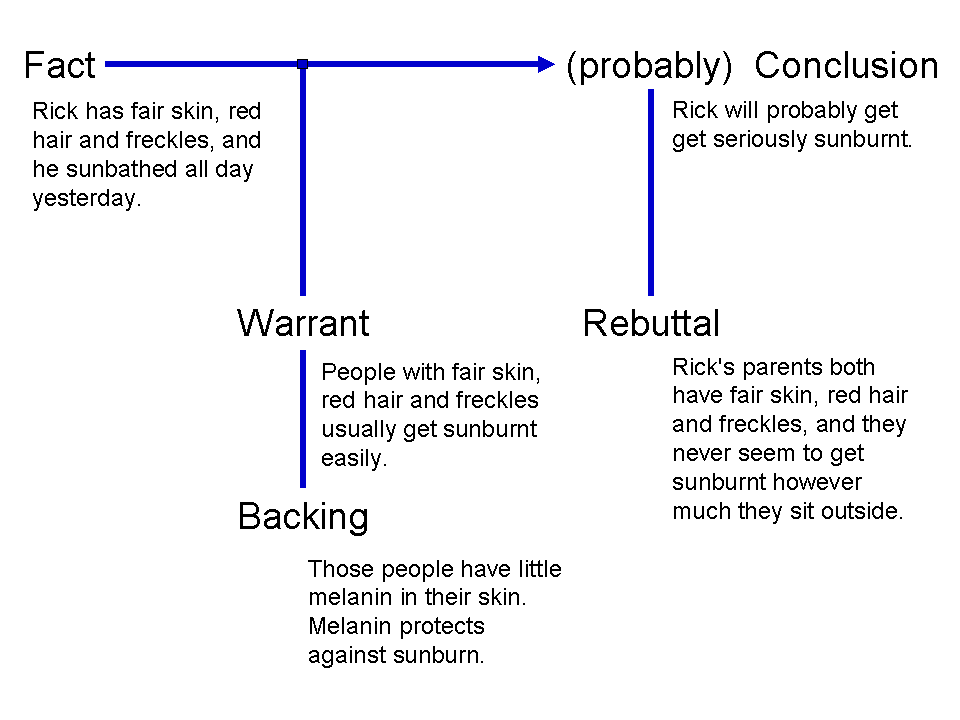
This shows the fundamental argumentative components.
- Claim - This is a point that the speaker/author is trying to make.
- Ground (Fact/Evidence/Data) - The source of truth on which the claim lies. A claim is made based upon a ground.
- Warrant - The statements that connect from the ground to the claim.
- Backing - The credentials provided to certify the warrant.
- Rebuttal - The possible conditions that might refute the claim. These can first be used to disagree with the warrant, which might further debase the claim.
- Qualifier - The phrases that express the strength granted by the warrant to the claim.
In these, Claim, Ground and Warrant are considered essential components and Backing, Qualifier and Rebuttal are non-essential and might not be needed in some arguments.
To demonstrate how the Toulmin’s argumentation model works, let’s take an example of why a certain hiring was done for a posting.
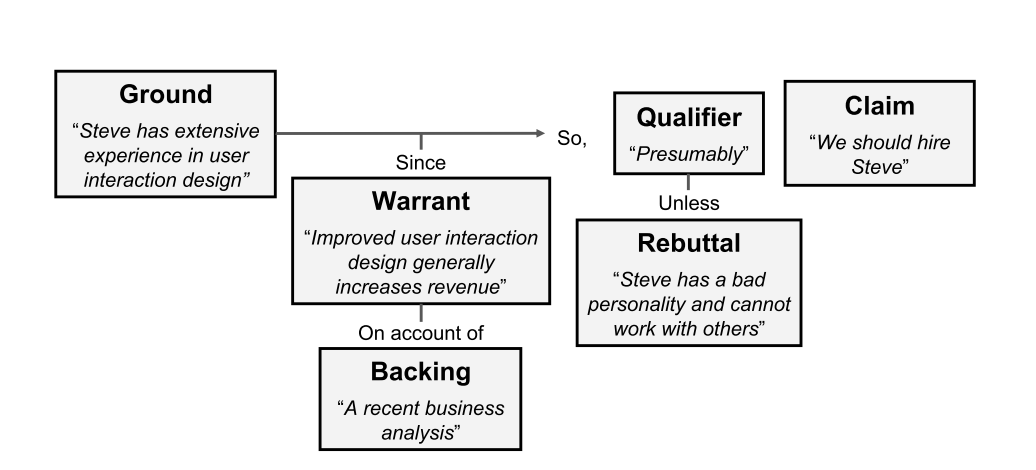
Argumentation Analysis
It’s best to go through the paper for issue selection and the reasoning behind it. I will skip the section as it is straightforward to understand.
Argumentation Model Adaption
While a simple claim-premise model can assure a better accuracy for classification, having a full model of argumentation can identify how the contributors can reason out the solutions for usability issues and prioritize them.
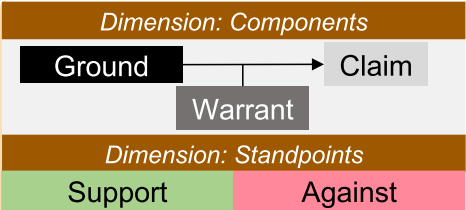
Some modifications were made to the Toulmin’s model based on the data.
- Warrant and Backing were merged into one component of the model and are called as Warrant. This is done because in a issue discussion thread, it is quite difficult to segregate these. Intuitively this makes sense, as the people involved in a issue discussion usually know what they are talking about and hence a backing is not mostly required.
- Rebuttal component is removed and the standpoint is tagged as Support or Against. This makes the automated classification a binary classification problem.
- Qualifier is excluded because of the low representation.
The reduced model looks like this.
Argumentation Model Application on Data
The data was extracted from GitHub using the APIs provided by them. Now obviously this data is unstructured and had to be scrubbed and formatted in the required state. As a first step, the data was classified as argumentative or non-argumentative. Then, the statements that are categorized as argumentative were taken and further classified independently into ground, warrant or claim and support or against.
Sentences containing multiple argumentation components were manually split and the phrases are referred as quotes.
Issue threads can contain more than one topics; all the quotes that discuss the same claim are defined as one argument.
This is what the data distribution looks like, for the 5 issue threads taken.

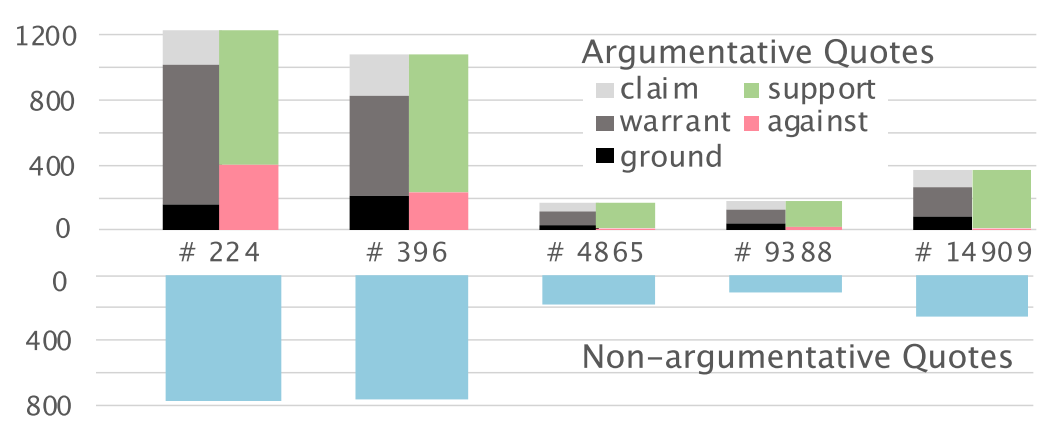
The researchers provide the following observations from the data.
- Since the non-argumentative comments constitute a large portion of the issue thread, one simple solution would be to hide them. This could prevent the information overload.
- Warrants are usually speculated usecases and personal opinions; OSS evolution is heavily influenced by the personal opinions and experiences.
- The discussion in the issue thread easily digresses into many related topics.
- Heavily disagreed arguments are usually in the middle of the issue thread; the arguments might be hard to recognize in a lengthy thread.
Machine Learning based Argument Extraction
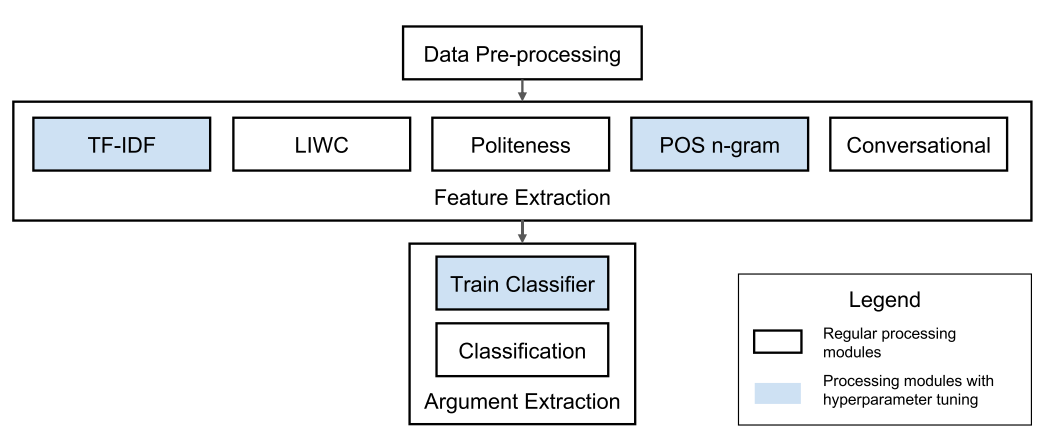
The pre-processing step involves tokenization and lemmatization, and replacing the special content with assigned tokens. Feature extraction involves extracting the textual and conversational features.
There are two main classifiers used - LinearSVM and Complement Naive Bayes models.
There is no feature selection done, to prevent loss of information from the text. This results in highly sparse datasets; LinearSVM yields state of the art performance for such data. Complement Naive Bayes was chosen as it yields good performance for smaller training sets, and is suited for imbalanced data.
The three classification tasks that were defined are
- Classifying Argumentative and Non-Argumentative quotes
- Classifying Claim, Warrant and Ground components
- Classifying Support and Against components
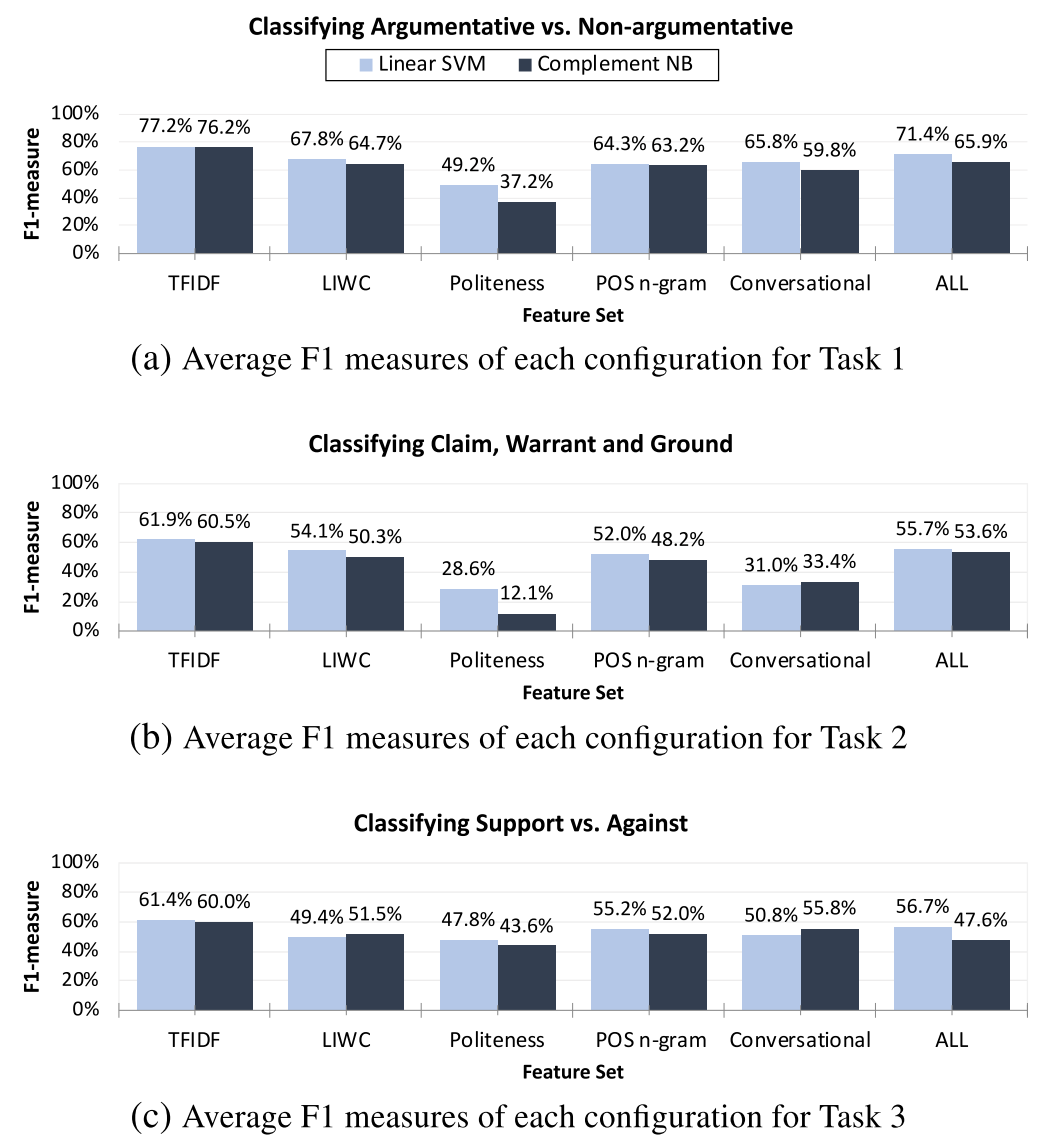
Researchers have provided following reasoning for the results.
- TF-IDF yields highest accuracy as this feature captures the domain specific words that the annotated corpus contains.
- Naive Bayes and SVM perform almost identically.
- The first level classification of Argumentative and Non-Argumentative quotes has higher accuracy than the other two, which can indicate the requirement of a larger training data.
There was an interesting practitioner evaluation done as part of usability testing. The results show a spike in developer productivity. I will not be covering it here since it would require a detailed explanation of the methadology, and I am mainly writing about the central idea of the paper.
Limitations and Future Work
One of the limitations that is discussed by the researchers is external validity that comes in due to the finite data that was chosen. While it becomes tedious to code, the concept can only be validated on extending it to other issues.
This model can be extended well with availability of labelled training data. Combining supervised and unsupervised approaches can reduce the manual effort that is required in this step.
Finally, speaking about the adaptability, the researchers mention that having a sophisticated visual design can underscore the usability of tool.
References for better conceptual understanding
- Analysis and Detection of Information Types of Open Source Software Issue Discussions
- Activity-Based Analysis of Open Source Software Contributors: Roles and Dynamics
- Argumentation mining in user-generated web discourse
- Back up your Stance: Recognizing Arguments in Online Discussions
- Reporting Usability Defects: A Systematic Literature Review
- Exploring Usability Discussions in Open Source Development
Thoughts
ArguLens is without argument an innovative application of mining the issue threads by structuring the comments in a classic argumentation model. I agree with the researchers that a sophisticated tool can accentuate the usability of the tool, but that might be a problem of UX design.
Having a larger dataset can be useful in outlining which ML model will be more efficient in modeling the conversations. We can take a page out of conversational modeling playbook to automatically tag the ground, claim and warrants. This might be a far-fetched goal but is a possible research direction.
The researchers have reasoned out that the reason heavily disagreed arguments are usually in the middle of the issue thread is because the disagreed arguments might be hard to recognize in a lengthy thread. It could also be because usually the discussion threads are closed once an agreement is reached. The beginning of the threads contain comments that usually outline the problem statement. If there are any disagreements, they would definitely lie in the middle of the thread. It is very rare that a issue will get closed on the note of a disagreement.
Researchers also mention that the warrants extracted in the experiment suggest that usability discussions are usually influenced by personal opinions and experiances. In my opinion this is a good thing, as the developers tend to work towards addressing the corner cases that have miniscule chance of breaking; making the software robust.
It is quite possible that the comment authors know each other outside the ITSs. This can lead to them coming to a consensus, without having a proper discussion on the discussion boards, thereby skewing the data.